Customer says “I need XXms latency.” What do you do? Break out the command line and ping from server A to server B. Numbers below what they asked for? Great. What happens when it’s higher than they need? I have a customer that is asking for less than 0.2 ms of latency between two Windows VMs. That sounds pretty easy right? Non blocking line rate networking, 25GB/s NICs, maybe even same host. What are the results?

Well that’s annoying. <1ms. Lets get hrping https://www.cfos.de/en/ping/ping.htm.

~.4ms????? What in the world? These are two Windows VMs on the same esx host on a standard vSwitch. How can it take half a ms for them to respond? Well as it turns out (and most network people will tell you) ICMP is a best effort protocol. This applies not only to forwarding on network devices but also to operating systems. Many years ago you could overload a host with ICMP traffic and generate a DoS attack on the machine by using all available CPU resources to respond to ICMP requests. As such modern (and not so modern) OSs relegate ICMP ping response to a lower priority. Many years ago I implemented a solution from NetQOS called SuperAgent. This was latter acquired by CA Technologies. The main thing SuperAgent does is identify latency sources on the network.
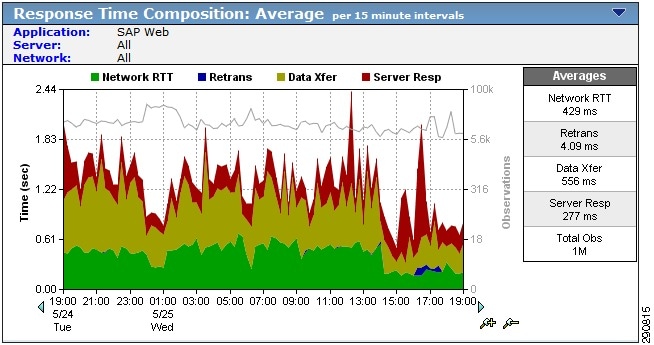
There are 4 different parts of latency that are broken down.
- Network Round Trip Time
- Retransmit Time
- Data Transfer Time
- Server Response Time
Network RTT is the actual network latency between machines. The best way to find that is to monitor traffic as close to the server as possible. In this case I did a packet capture on the machine. The time between the initial SYN packet and the replying SYN-ACK packet is the bet estimation of network latency. The server replies as soon as it can from the TCP stack. This does not include any application time as the connection setup is handled by the OS kernel. This is what I would give the customer as “network” latency.

Here Wireshark is displaying time as delta from the last frame displayed. Frame 23900 is the initial SYN. Frame 23903 is the replying SYN-ACK. This connection is from the same two Windows VMs as the ping test. One is hosting an HTTPS server. You can see the actual latency is .000098 seconds.
Retransmit Time and Data Transfer Time are pretty self explanatory. The only thing I would suggest understanding is TCP retransmission timers and timeouts. The short explanation is that if there is a dropped packet there is an increasing timer that slows the TCP connection down while waiting for the packet to arrive. https://support.microsoft.com/en-us/topic/how-to-modify-the-tcp-ip-maximum-retransmission-time-out-7ae0982a-4963-fa7e-ee79-ff6d0da73db8
Server response time is the time it takes for the server to respond to the initial request from the client. This can be measured by looking at the packets after the initial TCP connection setup and timing the response with payload. For instance in HTTP the GET request is sent and the server responds with data. The time between the GET request and response is the Server Response time. For unknown applications this can be tricky to determine but most applications will have a small request and a large reply.
So the customer asked for a latency of 0.2ms. ICMP showed a higher response time. The application itself gets a response time of 0.000098s or 0.098ms. Don’t use ping as a measure of latency. There are too many variables that affect the time.

One thought on “Ping is not a real latency measurement”